
Neural networks have always been at the bleeding edge of technological advancement, evolving at an impressive pace. Every so often, a fresh wave of innovation takes us by surprise and nudges the field forward. One such ripple is EfficientNet, a newer player in the grand theater of deep learning.
Now, before we delve into the labyrinthine details of EfficientNet, let’s take a small detour. Our previous articles have touched upon various crucial aspects of neural networks. For instance, our insightful piece on ResNet: A Powerhouse of Machine Vision elucidates the extraordinary capabilities of residual networks in the realm of machine vision.
Likewise, we dived deep into the intricate details of neural networks with pieces on the likes of VGGNet and AlexNet. Our journey has taken us from understanding the foundation of neural networks, as exemplified in our article on Multi-Layer Perceptron, to shedding light on convolutional operations with our deep dive into Convolutions: The Magic Behind Neural Networks. These articles form the backdrop to today’s discussion on EfficientNet.
Now, let’s pivot back to the star of our show – EfficientNet.
Pioneering a New Era
Just as the name suggests, EfficientNet is about efficiency, but the term ‘efficiency’ is not used in its colloquial sense. In the realm of machine learning, efficiency typically implies a blend of speed and accuracy, and EfficientNet strikes a commendable balance between the two. EfficientNet isn’t merely another addition to the growing family of neural networks. It’s a forward-thinking model that brings a new perspective to the table.
EfficientNet, in essence, is a meticulously engineered convolutional neural network (CNN) architecture. CNNs, as explained in our piece on Convolutions: The Magic Behind Neural Networks, have proven to be exceedingly competent at handling image-based tasks. So, what sets EfficientNet apart? Let’s find out.
The Fundamental Premise of EfficientNet
The aim of EfficientNet is to uniformly scale all dimensions of the network (depth, width, and resolution), which contrasts with previous methods that disproportionately scaled these dimensions.
This idea of uniform scaling, as introduced by Mingxing Tan and Quoc V. Le, is the fulcrum upon which EfficientNet balances. Conventionally, when we attempt to improve a neural network’s performance, we resort to scaling up its dimensions. This could mean increasing the depth (adding more layers), the width (adding more neurons to each layer), or the resolution (increasing the input image size). However, these dimensions are usually scaled haphazardly, which can lead to sub-optimal results.
Enter EfficientNet, which fundamentally changes the approach to scaling. Rather than scaling dimensions in isolation or randomly, EfficientNet employs a systematic methodology to uniformly scale all three dimensions. The results? Improved performance without a significant increase in computational cost.

Dissecting the EfficientNet Architecture
Moving forward, let’s examine the anatomy of the EfficientNet model. How does it function? What does it look like on the inside? To answer these questions, we must first discuss the principle of compound scaling, the beating heart of EfficientNet.
Compound Scaling: The Key to Efficiency
As we’ve learned, EfficientNet isn’t content with merely scaling one dimension of a network while keeping the others constant. It prefers a more balanced approach. But how does it determine the right way to scale? Enter the concept of compound scaling.
Compound scaling, a groundbreaking idea proposed by Tan and Le, is an optimization strategy that simultaneously scales the width, depth, and resolution of the network. This methodology is guided by a simple yet elegant formula:
width ~ depth ~ resolution = 𝛼^(Φ), 𝛽^(Φ), γ^(Φ) (where 𝛼 * 𝛽 * γ = 2 and 𝛼 >= 1, 𝛽 >= 1, γ >= 1)
Here, Φ is a user-defined coefficient that controls how much additional resources are available, while 𝛼, 𝛽, and γ determine how these resources should be allocated among the width, depth, and resolution, respectively.
The compound scaling rule is central to EfficientNet’s ethos. It ensures that every unit of resource (for example, computational power) is used to increase the network’s dimensions in the most balanced way possible.
In our article on The Art of Regularization: Taming Overfitting, we explored strategies to avoid overfitting. Compound scaling takes this concept a step further, ensuring not just the avoidance of overfitting, but also an effective utilization of resources for an optimally performing model.
EfficientNet’s Models
The EfficientNet architecture comprises several models, each designated by a letter from B0 to B7. The base model, B0, was developed through a thorough neural architecture search. Then, the compound scaling method was applied to this baseline model to develop the rest of the EfficientNet models.
With each subsequent model (from B1 to B7), the depth, width, and resolution increase, following the compound scaling principle. As you move up the ladder, you’ll notice that the models require more computational resources but offer improved accuracy in return.
Key Advantages of EfficientNet
At this point, we understand what EfficientNet is and the philosophy it upholds. But why does this matter? What benefits does EfficientNet bring to the table?
- Greater Efficiency: EfficientNet is designed to maximize efficiency. By adhering to the principle of compound scaling, it ensures that all network dimensions are scaled uniformly, resulting in improved performance without an exponential increase in resources.
- Improved Accuracy: Thanks to its innovative design, EfficientNet manages to squeeze out higher accuracy from the same computational budget compared to other models. This is a monumental achievement in the world of deep learning.
- Versatility: The range of EfficientNet models (from B0 to B7) allows researchers to select a model based on their specific computational budget and accuracy needs. This flexibility is invaluable, making EfficientNet applicable across a wide range of tasks and settings.
Diving Deeper: Applications and Impact of EfficientNet
Now that we have a grip on what EfficientNet is and its technical intricacies, let’s explore its practical applications and the impact it has on the world of machine learning.
Unleashing the Power of EfficientNet
From diagnosing diseases in medical imaging to improving object detection in autonomous vehicles, EfficientNet’s application is vast and transformative. Due to its impressive performance metrics, it’s been successfully employed in various fields requiring image classification tasks. Here are a few examples:
- Medical Imaging: EfficientNet’s high efficiency and accuracy make it an excellent choice for tasks such as disease detection in medical scans, where a slight increase in accuracy can have profound real-world implications.
- Autonomous Vehicles: EfficientNet aids in better object detection and recognition, which is vital for the functioning of autonomous vehicles.
- Agriculture: In precision farming, EfficientNet can assist in identifying plant diseases, enabling timely intervention and treatment.
EfficientNet in Context: Comparing with Other Models
To better appreciate EfficientNet’s impact, let’s place it within the context of its contemporary models. While we’ve previously explored a variety of neural networks in depth, from ResNet, VGGNet, to AlexNet, it’s enlightening to see how EfficientNet stacks up against these machine learning titans.
EfficientNet vs. ResNet: EfficientNet, with its focus on balancing all dimensions of the network (depth, width, and resolution), allows for improved performance with less computational expense compared to ResNet. While ResNet introduced the groundbreaking concept of residual connections to mitigate the vanishing gradient problem, EfficientNet takes it a step further by optimizing for efficiency.
EfficientNet vs. VGGNet: Compared to VGGNet, EfficientNet delivers superior performance with significantly fewer parameters. This reduced complexity not only makes EfficientNet lighter and faster but also less prone to overfitting.
EfficientNet vs. AlexNet: AlexNet was a seminal model that sparked interest in deep learning. While it was innovative in its time, EfficientNet outperforms AlexNet both in terms of accuracy and efficiency, thanks to advancements like compound scaling.
Digging Deeper: Understanding Compound Scaling in EfficientNet
Now that we’ve provided an overview of EfficientNet and compared it to other models, it’s time to dive deeper into one of its key components: compound scaling. As mentioned before, compound scaling plays a vital role in making EfficientNet models efficient and compact without compromising on performance. But how does it work? Let’s explore.
Compound scaling is the idea of balancing all dimensions of the network, such as the depth, width, and resolution. Unlike traditional scaling methods that focus on a single dimension, compound scaling strategically scales all dimensions simultaneously.
Here’s how each of these dimensions contribute to a neural network’s performance:
- Depth: Depth of a network corresponds to the number of layers. More layers can help the model learn more complex features but at the cost of increased computational resources and the risk of overfitting.
- Width: Width relates to the number of neurons in a layer. Wider networks can learn more nuanced features but may struggle with small-scale patterns.
- Resolution: Resolution refers to the input size of the image. Higher resolution can help identify intricate details, but it requires more processing power.
To keep these three dimensions in check, EfficientNet introduces a compound coefficient, denoted by φ, to scale up these factors in a fixed ratio. If we have an initial baseline network, the depth (D), width (W), and resolution (R) for the new network can be determined as:
D = α^(φ) * D_baseline
W = β^(φ) * W_baseline
R = γ^(φ) * R_baselinewhere α, β, and γ are constants that determine how much each dimension is scaled, and they are determined by a grid search on the original baseline network.
The beauty of compound scaling lies in the harmony it creates among these dimensions. By increasing all dimensions in tandem, it maintains the balance in the network’s architecture, allowing it to learn more complex patterns without significantly increasing computational complexity.
In other words, with compound scaling, we are not just mindlessly adding layers or neurons, or increasing the resolution. We’re doing so in a highly calculated, harmonious way that optimizes for both accuracy and efficiency. And that’s the cornerstone of EfficientNet’s impressive performance.
The Symphony of EfficientNets: A Tale of Variants from B0 to B7
Just like a melody evolves with every note, the EfficientNet family expands with various models, each one a harmonious blend of depth, width, and resolution scaling. Each member of the family, named from B0 to B7, carries distinct features fine-tuned to cater to a variety of computational capacities and performance requirements.
B0: The Progenitor
B0, the foundation stone of the EfficientNet family, was built upon a baseline model designed using a neural architecture search. It’s an intricate work of art, leveraging the power of depthwise convolutions while keeping computational efficiency in mind. Despite its relatively smaller size, B0 delivers commendable performance, setting the stage for its powerful successors.
B1 to B7: Evolution Unleashed
Building upon the foundation of B0, the subsequent EfficientNet models B1 to B7 apply the compound scaling method, creating a symphony of models tuned for diverse application needs.
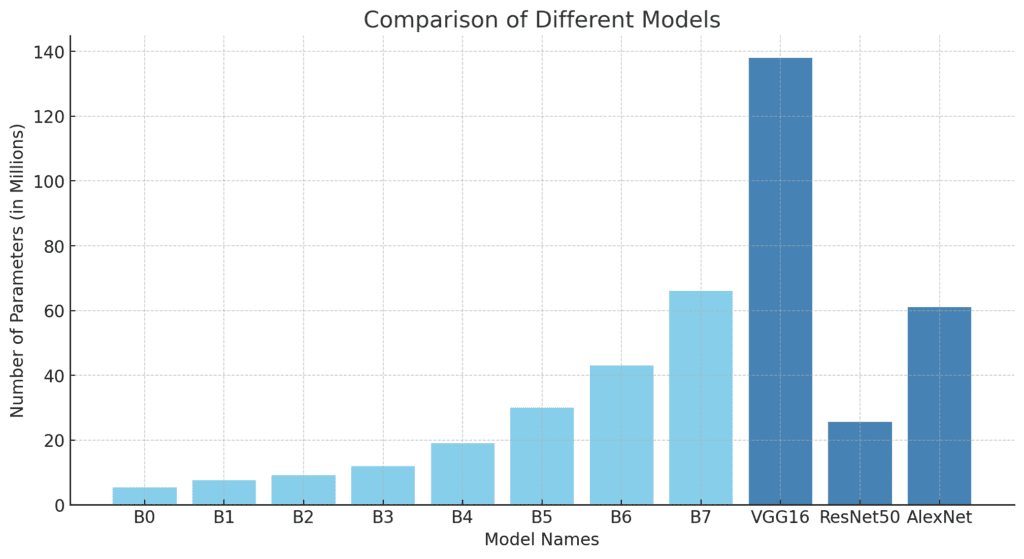
- EfficientNet-B1: With an expanded image size of 240×240 and 7.6M parameters, B1 brings into play a 1.1x depth, 1.0x width, and 1.15x resolution.
- EfficientNet-B2: Catering to a 260×260 image size, B2 comprises 9.2M parameters and scales B1 by a factor of 1.1x depth, 1.1x width, and 1.15x resolution.
- EfficientNet-B3: B3 pushes the boundaries further with a 300×300 image size, 12M parameters, and scaling factors of 1.2x depth, 1.2x width, and 1.15x resolution.
- EfficientNet-B4: With a significant jump, B4 operates on a 380×380 image size, entails 19M parameters, and factors of 1.4x depth, 1.4x width, and 1.15x resolution.
- EfficientNet-B5: Scaling further, B5 caters to a 456×456 image size, comprises 30M parameters, and scaling factors of 1.6x depth, 1.6x width, and 1.15x resolution.
- EfficientNet-B6: B6 leaps forward to manage a 528×528 image size, wields 43M parameters, and scaling factors of 1.8x depth, 1.8x width, and 1.15x resolution.
- EfficientNet-B7: The pinnacle of the family, B7, is equipped to handle a 600×600 image size, holds a whopping 66M parameters, and uses scaling factors of 2.0x depth, 2.0x width, and 1.15x resolution.
As we ascend from B0 to B7, the models steadily increase their capacity, tackling larger image sizes and becoming more sophisticated. Each variant in the family has been carefully crafted to strike a balance, enhancing performance without unnecessarily increasing computational complexity. They are the demonstration of the EfficientNet philosophy, embodying the promise of doing more with less.
The Future of EfficientNet
EfficientNet has opened up a new pathway in deep learning, setting the stage for models that not only perform better but also do so more efficiently. As we continue to unravel the potential of machine learning, the principles that guide EfficientNet, such as compound scaling, may play a pivotal role in shaping future innovations.
The widespread adoption and success of EfficientNet has demonstrated the importance of efficiency in machine learning models. As we’ve previously discussed in our article on Demystifying Multi-Layer Perceptron: The Unsung Hero of Neural Networks, simple yet powerful ideas can lead to significant progress in the field of machine learning. EfficientNet is no different.
In our series of articles, we’ve explored the world of neural networks, from the classic AlexNet: The Breakthrough in Deep Learning to the intricate Dancing with DenseNets: A Symphony of Neural Networks. EfficientNet stands out in this lineage as a testament to the evolution of machine learning. It’s a reminder of the constant endeavor in the world of AI: to not only aim for improved performance but to do so in an increasingly efficient and effective manner.
Leave a Reply