
It’s impossible to stroll through the park of Machine Learning (ML) without crossing paths with the evergreen entity known as the Neural Network. You might have already met its sophisticated cousins – the Convolutional Neural Networks, AlexNet, and perhaps flirted with the concepts of overfitting and regularization. Today, however, let’s meet the unsung hero of the family: the Multi-layer Perceptron (MLP).
Enter the MLP
Multi-layer Perceptron, or MLP, is a class of feedforward artificial neural network that has seen a wide range of applications – from image recognition to natural language processing. An MLP consists of at least three layers of nodes—a stark contrast to the traditional perceptron’s singular layer. However, this seemingly simple addition transforms the way it handles data, resulting in a ‘quantum leap’ in its computational capabilities.
Multi-layer Perceptron: not a show-stopper, but a steadfast workhorse of the Neural Network landscape.
Consider the MLP as a diligent workhorse, carrying out essential tasks behind the scenes, ensuring that the entire neural network operates smoothly. Its numerous layers allow it to handle a vast array of problems, including the non-linear ones that were beyond the reach of its predecessor, the simple perceptron.
How it Works
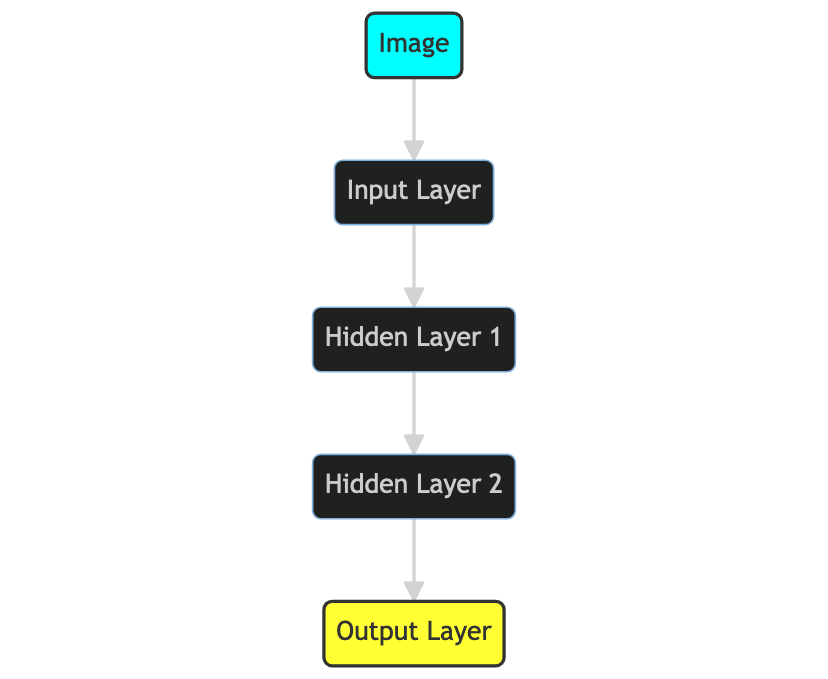
An MLP is made up of an input layer, one or more hidden layers, and an output layer. Each layer is fully connected to the next, meaning each node, or ‘neuron’, in one layer connects with every neuron in the following layer. This multi-layered, fully connected structure forms the essence of the MLP, allowing it to ‘learn’ from more complex, higher-dimensional data.
- Input Layer: The MLP starts here. The number of neurons in this layer equals the number of input features.
- Hidden Layers: These are where the MLP’s magic happens. Each neuron takes in the outputs from all the neurons of the previous layer, applies a weight, adds a bias, and runs them through an activation function.
- Output Layer: This is the destination of the MLP journey. The final output corresponds to the class labels for classification problems or the predicted values for regression problems.
The Math behind MLP: Unraveling Non-Linearity
One of the significant strengths of the MLP is its ability to model non-linear relationships. This non-linearity is introduced by incorporating ‘activation functions’ in the neurons of the MLP’s hidden layers. Let’s take a closer look at how this works.
Activation Functions: The Architects of Non-Linearity
In the context of neural networks, an activation function decides whether a neuron should be activated or not by calculating a weighted sum and adding bias. It helps to normalize the output of each neuron to a range between 1 and 0 or between -1 and 1.
There are several activation functions you might encounter, each with its unique characteristics and use cases. The most commonly used ones are the sigmoid function, the hyperbolic tangent function (tanh), and the rectified linear unit (ReLU). These functions allow MLPs to model complex, non-linear relationships between inputs and outputs, giving them an edge over simpler, linear models.
The non-linearity introduced by activation functions adds a splash of creativity to the logical world of neural networks, allowing them to capture complex patterns in data.
The implementation of an activation function looks something like this:
- Input: An MLP takes a set of inputs, which could be an array of pixel values from an image or encoded text data.
- Weights and Bias: Each input is multiplied by a weight, and a bias is added. The bias helps to shift the activation function left or right, aiding the MLP in finding the best fit.
- Summation: The results are then summed, creating a weighted sum.
- Activation: The activation function is applied to this weighted sum, introducing non-linearity into the model and ensuring the output stays within a manageable range.
And voila! That’s the hidden layers of MLP in action. This procedure is carried out for every single neuron in the hidden layers, with each neuron learning different features of the input data. It’s a bit like a team of detectives, each focusing on a different aspect of the case until, collectively, they crack it.
The Learning Mechanism: Backpropagation
The real power of MLPs, and indeed all neural networks, lies in their ability to learn from their mistakes. This is where a process known as backpropagation comes in. In essence, backpropagation involves going back through the network, adjusting the weights and biases to minimize the difference between the predicted output and the actual output.
However, don’t be fooled by the apparent simplicity of backpropagation. It’s a potent algorithm that leverages the chain rule of calculus to achieve its goal. By incrementally adjusting the weights and biases, the network learns the optimal parameters to predict the correct output. It’s a bit like a self-improvement regimen for the network, pushing it to become better with each iteration.
MLP: Making a Mark in Real-World Applications
While the technical intricacies of MLPs are fascinating, their true value shines in their application across various fields. Let’s explore a few.
Handwriting Recognition
The origins of MLPs are rooted in handwriting recognition, dating back to when Yann LeCun introduced the LeNet-5 architecture in 1998. It was an early example of a convolutional neural network, a close cousin of the MLP, and was adopted by banks around the world to recognize handwritten numbers on checks. This advancement was nothing short of groundbreaking and paved the way for further applications of MLPs in image recognition tasks. For more about the evolution of such networks, check out our article on AlexNet: The Breakthrough in Deep Learning.
Sentiment Analysis
With the advent of social media, businesses have been trying to understand customer sentiment in real time to tailor their marketing strategies. MLPs have been integral in solving this problem by classifying text data as positive, negative, or neutral based on the words and context.
Medical Diagnosis
MLPs have been playing an increasingly important role in the field of healthcare, especially in medical diagnosis. By learning complex patterns and anomalies in medical images and patient records, MLPs can aid doctors in diagnosing a range of diseases more accurately and efficiently.
Despite their many applications, MLPs, like all models, have their limitations. It is crucial to ensure they are used judiciously to avoid common pitfalls such as overfitting. Our article Beware of Overfitting: A Subtle Saboteur provides a more in-depth exploration of this topic.
Conclusion: Your Journey with MLP
The multi-layer perceptron is a powerful and flexible tool in the machine learning toolkit. Whether it’s recognizing handwritten digits, analyzing customer sentiment, or diagnosing diseases, MLPs have proven their mettle across a wide range of applications.
Yet, the journey with MLPs doesn’t end here. As you delve deeper into the realm of machine learning, you will encounter more complex and fascinating models, each with its own strengths and weaknesses, and each deserving of your time and understanding.
Keep exploring, keep learning, and remember: the world of machine learning, with all its layers and nodes, is at your fingertips. Don’t stop at MLPs – they are just the beginning.
Leave a Reply